
[DL/CV/PRJ] Image Classification DL 모델 만들기 1
Image Classification 문제에서 왜 CNN이 필요한지 알아보자.
| 의류 이미지 구분 DL 프로젝트 |
Code
without CNN
import tensorflow as tf
# Download dataset
(trainX, trainY), (testX, textY) = tf.keras.datasets.fashion_mnist.load_data()
# Model
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(28,28), activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
# Train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(trainX, trainY, epochs=10)
with CNN
import tensorflow as tf
# Pre-processing
(trainX, trainY), (testX, testY) = tf.keras.datasets.fashion_mnist.load_data()
trainX = trainX / 255.0
testX = testX / 255.0
trainX = trainX.reshape( ( trainX.shape[0], 28, 28, 1 ))
testX = testX.reshape( ( testX.shape[0], 28, 28, 1 ))
# Model
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D( (2, 2) ),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
# Train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(trainX, trainY, validation_data=(testX, testY), epochs=5)
# Predict
# score = model.evaluate(testX, testY)
1. 이미지 데이터를 그냥 딥러닝 돌려보면?(CNN 사용X)
1) Dataset
import tensorflow as tf
import matplotlib.pyplot as plt
# Download dataset
(trainX, trainY), (testX, textY) = tf.keras.datasets.fashion_mnist.load_data()
print(trainX[0])
print(trainX.shape)
--------------------------------------------------------------------------------
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
...
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]
(60000, 28, 28)
print(trainY)
print(trainY.shape)
--------------------------------------------------------------------------------
[9 0 0 ... 3 0 5]
(60000,)
np.unique(trainY)
--------------------------------------------------------------------------------
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8)
plt.imshow(trainX[0])
plt.gray()
plt.colorbar()
plt.show()
2) Model
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(28,28), activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
--------------------------------------------------------------------------------
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_15 (Dense) (None, 28, 128) 3712
dense_16 (Dense) (None, 28, 64) 8256
flatten (Flatten) (None, 1792) 0
dense_17 (Dense) (None, 10) 17930
=================================================================
Total params: 29,898
Trainable params: 29,898
Non-trainable params: 0
_________________________________________________________________
input_shapemodel.summary()를 보기 위해서는 반드시 첫번째 layer에input_shape를 넣어줘야 한다.input_shape에는 데이터 1개의 shape를 넣어준다.- trainX의 shape=(60000, 28, 28)
- input_shape=(28,28)
- Activation function 중
relu함수 중 음수는 모두 0으로 만들어주므로 convolution layer에서 자주 쓴다.- 확률은 minus 값이 나오면 안되니까.
Softmax- 0~1 사이의 값
- Multi-Category Classification 예측 문제이므로 활성함수로
softmax를 사용한다 - 마지막 노드 갯수는 카테고리 갯수
- 예측한 모든 확률을 더하면 1
- (비교)
Sigmoid- 0~1 사이의 값
- Binary Classification 예측 문제에는 활성함수로
sigmoid사용 - 마지막 노드 갯수는 1개
- 확률의 총합이 1은 아님. 큰 출력값을 보일수록 해당 클래스를 나타낼 가능성이 높다.
tf.keras.layers.Flatten()- 2D 또는 3D 행렬 데이터를 1D로 압축해주는 Flatten 레이어
- ex) [ [1,2,3,4], [5,6,7,8] ] → [ 1,2,3,4,5,6,7,8 ]
3) Train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(trainX, trainY, epochs=10)
--------------------------------------------------------------------------------
Epoch 1/10
1875/1875 [==============================] - 10s 5ms/step - loss: 1.3431 - accuracy: 0.7847
...
Epoch 9/10
1875/1875 [==============================] - 9s 5ms/step - loss: 0.3385 - accuracy: 0.8784
Epoch 10/10
1875/1875 [==============================] - 9s 5ms/step - loss: 0.3283 - accuracy: 0.8800
- 카테고리 예측문제에서 쓰는 loss function
categorical_crossentropy:train_Y가 원핫인코딩되어 있을 때sparse_categorical_crossentropy:train_Y가 0,1,2,… 등 정수로 되어 있을 때
4) 요약
- 위에서 짰던 모델은
- 이미지의 픽셀데이터를 2차원의 28x28 행렬로 바꿔서,
- Flatten layer를 적용하고,
- 마지막에 1차원의 리스트를 출력.
- 그런데 데이터가 이미지일 때 이런 모델을 만들면 문제가 많아진다.
- 이미지를
Flatten해버렸기 떄문에 이미지를 해체해서 딥러닝을 돌리는 것과 마찬가지. 이미지가 더 이상 이미지 그 자체로의 분석이 어려워지고, 이미지의 특성을 추출하기 어려워진다. Convolution layer를 이용하면 현재 이미지의 특성을 추출하여 딥러닝 모델을 학습시킬 수 있다.- 즉, 사람얼굴 이미지라면 사람의 눈, 코, 입과 같은 특성을 추출할 수 있게 된다.
- 이렇게 이미지 데이터를 활용한 딥러닝 모델의 성능을 올릴 수 있다.
- 이미지를
2. 해결책은 CNN!
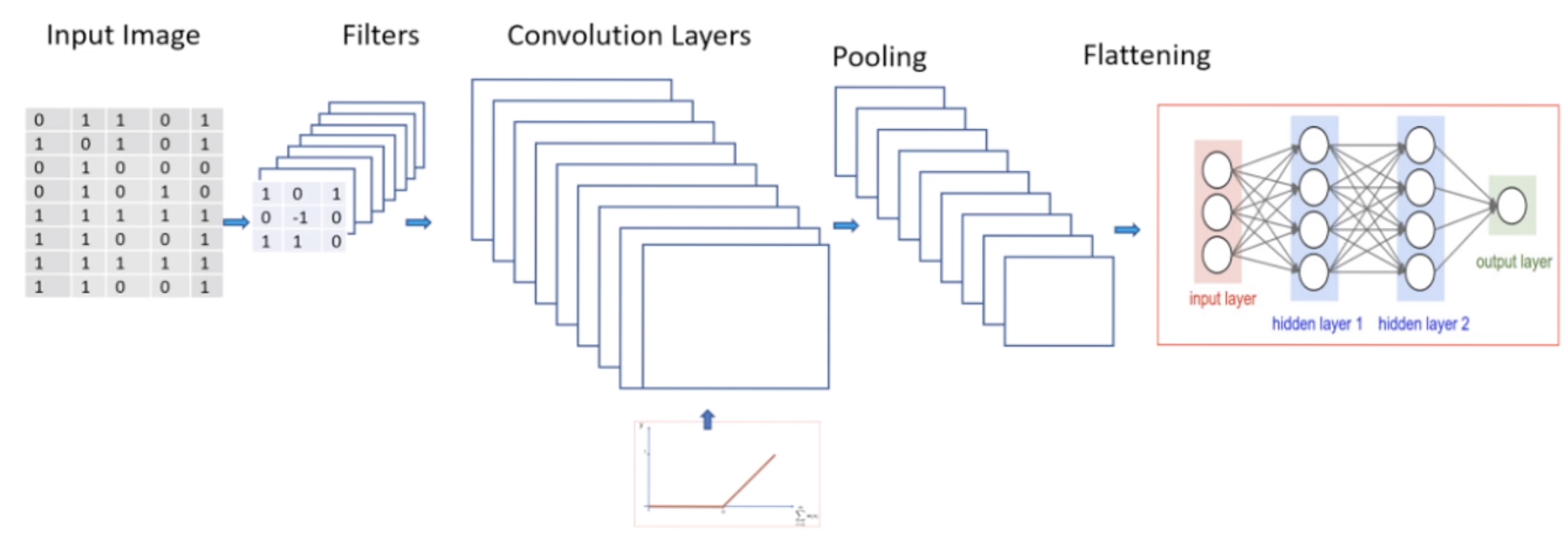
1) Feature Extraction
이미지를 해체하지 말고, 이미지 자체로 해석하자!
Filter(=kernel)을 이용하여 이미지에서 중요한 정보를 추출한 이미지 복사본(feature map)을 만든다.- 이렇게 추출한 이미지의 특성들은 서로 다른 점을 강조하게 된다. (세로선, 가로선, 동그란 부분, blur, sharpen, …)
- 이 과정을
Feature Extraction이라고 부르며, 이렇게 얻은 데이터로 학습한다.
2) Pooling Layer
- 단순히
Convolutional layer(filter를 통해 이미지의 특징 추출)만 적용하면 문제점이 있다. 이미지 내 feature의 위치가 달라지면 해당 feature를 판별하지 못하게 되는 것이다. - 예를 들어, 이미지 내 ‘자동차 바퀴’의 위치가 왼쪽 하단에 있는 이미지를 학습시켰는데 새로운 이미지에서는 왼쪽 상단에 ‘자동차 바퀴’가 있다면 새로운 이미지에서 ‘자동차 바퀴’ feature를 감지하지 못할 수도 있다는 것이다. 전혀 응용력이 없다!
- 이를 해결하기 위해
Pooling Layer를 사용한다.

Pooling Layer는 무엇?
- Pooling layer: 이미지의 중요한 부분을 유지한 채로 축소해서 가운데로 옮기는 레이어다.
- Pooling layer의 종류
- Max Pooling: 최댓값만 추림. 가장 많이 쓴다.
- Average Pooling: 평균값으로 추림
Convolutional layer + Pooling layer를 함께 쓰면특징추출 + 특징 가운데 모으기의 장점!- 이미지 내 feature가 어떤 위치에 있어도 모델이 잘 인식하게 된다. 즉, 이미지의 위치에 영향을 받지 모델을 만들고 싶을 때 활용하면 좋다.
- 이러한 응용력 있는 모델을
Translation Inavariance라고 한다.
3) CNN 전체 구조
- Input image와 Neural Network 사이에 Convolution 구조 존재
3. CNN 모델을 활용한 이미지 데이터 분류
1) Model
import tensorflow as tf
(trainX, trainY), (testX, testY) = tf.keras.datasets.fashion_mnist.load_data() # numpy.ndarray
trainX = trainX / 255.0
testX = testX / 255.0
# numpy array reshape
trainX = trainX.reshape( ( trainX.shape[0], 28, 28, 1 )) # trainX.shape = (60000, 28, 28)
testX = testX.reshape( ( testX.shape[0], 28, 28, 1 )) # testX.shape = (10000, 28, 28)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D( (2, 2) ),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
----------------------------------------------------------------------
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 28, 28, 32) 320
max_pooling2d_2 (MaxPooling (None, 14, 14, 32) 0
2D)
flatten_1 (Flatten) (None, 6272) 0
dense_1 (Dense) (None, 128) 802944
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 804,554
Trainable params: 804,554
Non-trainable params: 0
_________________________________________________________________
2) Train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(trainX, trainY, validation_data=(testX, testY), epochs=5)
----------------------------------------------------------------------
Epoch 1/5
1873/1875 [============================>.] - ETA: 0s - loss: 0.3833 - accuracy: 0.8651
...
Epoch 4/5
1875/1875 [==============================] - 11s 6ms/step - loss: 0.1806 - accuracy: 0.9329 - val_loss: 0.2582 - val_accuracy: 0.9065
Epoch 5/5
1875/1875 [==============================] - 12s 6ms/step - loss: 0.1522 - accuracy: 0.9441 - val_loss: 0.2524 - val_accuracy: 0.9158
<keras.callbacks.History at 0x286a26a10>
Test dataset이 따로 있다면, 아래 코드로 평가한다.
score = model.evaluate(testX, testY)
print(score)
trainX = trainX / 255.0,testX = testX / 255.0- 정수 0~255를 넣는 것이 아니라 미리 0~1로 압축해서 넣는 것이 좋을 때가 많다(선택사항).
- 더 좋은 결과가 나올 수도 있고, 처리시간도 단축하는 효과
tf.keras.layers.Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(28,28,1))- 32개의 서로 다른 feature 생성해줘. (32개의 이미지 복사본 생성. Keras가 알아서 32개의 서로 다른 커널 적용해준다)
(3, 3): Kernel 가로세로 사이즈 (Kernel size도 실험적으로 결과 잘 나올 때까지 변경해준다)padding='same': Convolution 적용하면 이미지가 작아지는데 이미지 사이즈를 input image와 똑같이 맞춰주는 것.- 왜
relu활성함수 쓸까? → 이미지를 숫자로 바꾸면 0~255 사이 값이다. (이미지에서는 음수 데이터 있으면 안돼) input_shape=(28,28,1): Conv2D는 4차원 데이터 입력 필요. 따라서 흑백 이미지라면(60000,28,28,1), 컬러 이미지라면(60000,28,28,3)형태로 넣어줘야 한다.(60000,28,28)형태로 넣으면ndim에러가 뜬다.
- Epoch 1회 끝날 때마다 채점하는 법
model.fit()안에validation_data=(X,Y)설정
- Train 후에 나타나는 accuracy가 validation/evaluation 후에 나타나는 accuracy보다 높은 이유
- Overfitting 현상 (training 데이터셋을 외움)
- Validation의 장점
- Epoch을 너무 많이 돌려서 학습이 많이 되면 overfitting이 될 확률이 커지는데 overfitting이 일어나기 전에 정지시켜서 그 때의 모델을 뽑을 수 있다.
- Val_accuracy 높일 방법을 찾자!
- Dense layer 추가?
- Conv + Pooling layer 추가?
3) 결론
- CNN을 활용한 모델을 만드니 accuracy가 올라갔다. (88% → 91%)
- CNN 모델에서 Feature Extraction(
Convolutional layer + Pooling layer)을 통해 이미지의 특징을 추출해서 가운데로 모으는 역할이 이미지 데이터를 활용하는 모델의 성능에 큰 역할을 한다는 것을 알 수 있다.

Leave a comment