
[NLP] Word2Vec
one-hot encoding의 단점은 벡터 표현에 단어 간의 관계를 전혀 나타내지 못한다는 점이다. 단어를 벡터로 바꿀 때, 벡터에 단어의 의미를 담고, 비슷한 의미의 단어들은 비슷한 벡터로 표현하고, 단어 간의 관계를 벡터를 통해 나타낼 수 있도록 하는word embedding model중 대표적인 모델로word2vec이 있다.
예를 들어, ‘왕’과 ‘여왕’의 관계가 ‘남자’와 ‘여자’의 관계라는 것을 벡터를 통해 알아낼 수 있도록 하는 것이다.
word2vec은one-hot encoding보다 단어의 의미를 효과적으로 표현하기 때문에 더 높은 학습 성능을 보인다.
💡 한국어 단어에 대해서 벡터 연산을 해볼 수 있는 사이트 (Korean Word2Vec)
- 각 단어 벡터가 단어 벡터 간 유사도를 반영한 값을 가지고 있기 때문에 단어가 가지고 있는 의미들로 연산을 하는 것처럼 보인다.
ex) 한국 - 서울 + 도쿄 = 일본
1. 개념
- word2vec은 ‘비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다’라는 가정을 통해 학습을 진행한다.
- 단어의 주위만 보아도 어떤 단어가 적합하고 부적합한지 어느정도 알 수 있다. 같은 위치에 들어가는 단어들은 서로 비슷한 맥락의 단어들이다. 따라서, 이렇게 비슷한 맥락을 갖는 단어에 비슷한 벡터를 준다.
- word2vec은
predictive method방식에 속하며, 이는 맥락으로 단어를 예측하거나 단어로 맥락을 예측하는 문제를 마치 지도학습(supervised learning)처럼 푸는 것을 말한다. - word2vec 알고리즘이 지도학습처럼 보이지만, 비지도학습(unsupervised learning) 알고리즘이다.
2. 알고리즘
- word2vec의 학습방식에는 CBOW(Continuous Bag of Words)와 Skip-Gram 2가지 모델이 있다.
CBOW는 주변단어들로 중간에 있는 단어들을 예측하는 방법이고,Skip-Gram은 중간에 있는 단어들로 주변단어들을 예측하는 방법이다.
1) CBOW
주변단어(즉, 맥락(context))로중심단어(target word)를 예측하는 문제를 푼다.- 주변단어는 타겟단어의 앞뒤 몇 단어를 의미하며, 주변단어의 범위를
window라 부른다. - word2vec은 데이터셋을 만들때
sliding window방식을 사용한다. 이는window size가 정해지면 window를 옆으로 움직이면서 주변단어와 중심단어를 바꿔가며 학습을 위한 데이터셋을 만드는 방식이다. - CBOW 인공신경망의 input layer에는 window size 범위 내의 주변단어들의 one-hot vector가 들어가고, output layer에는 예측하고자 하는 중심단어의 one-hot vector의 레이블이 필요하다.
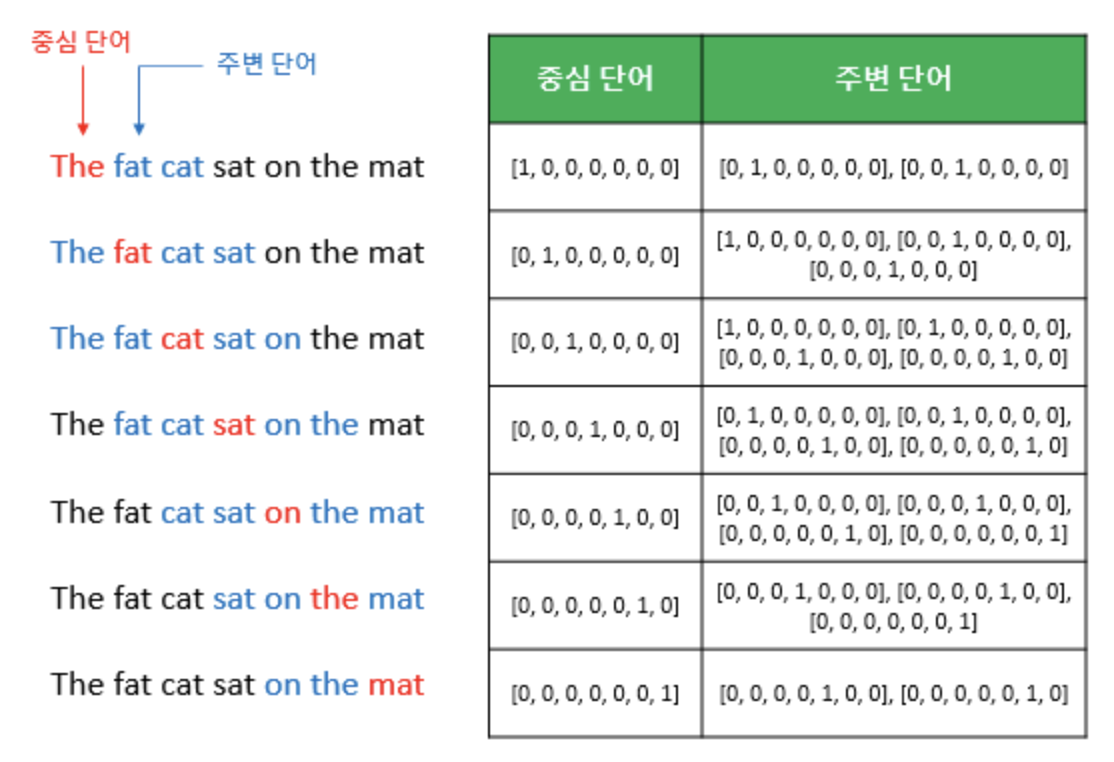 CBOW에서 window size=2일 때 sliding window 방법으로 dataset을 만드는 과정
CBOW에서 window size=2일 때 sliding window 방법으로 dataset을 만드는 과정
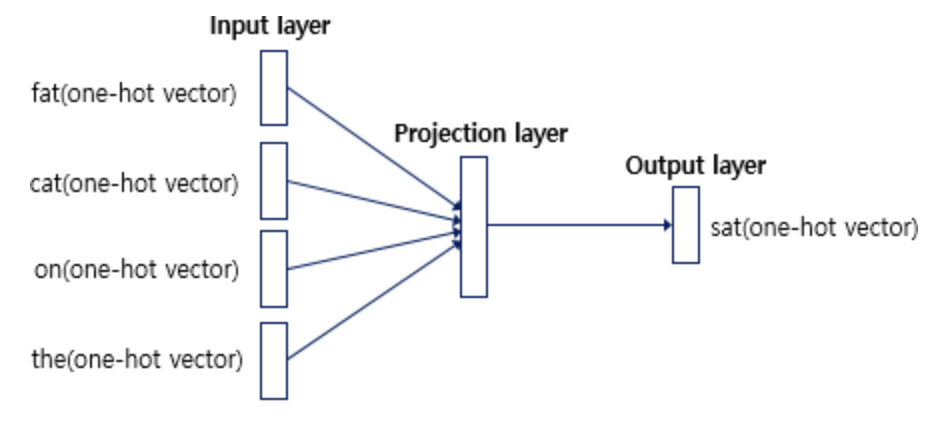 CBOW 인공신경망
CBOW 인공신경망
2) Skip-Gram
- 중심단어를 이용해 주변단어를 예측한다.
- 전반적으로 skip-gram이 CBOW보다 성능이 뛰어난 것으로 알려져 있으며, 더 널리 쓰이고 있다.
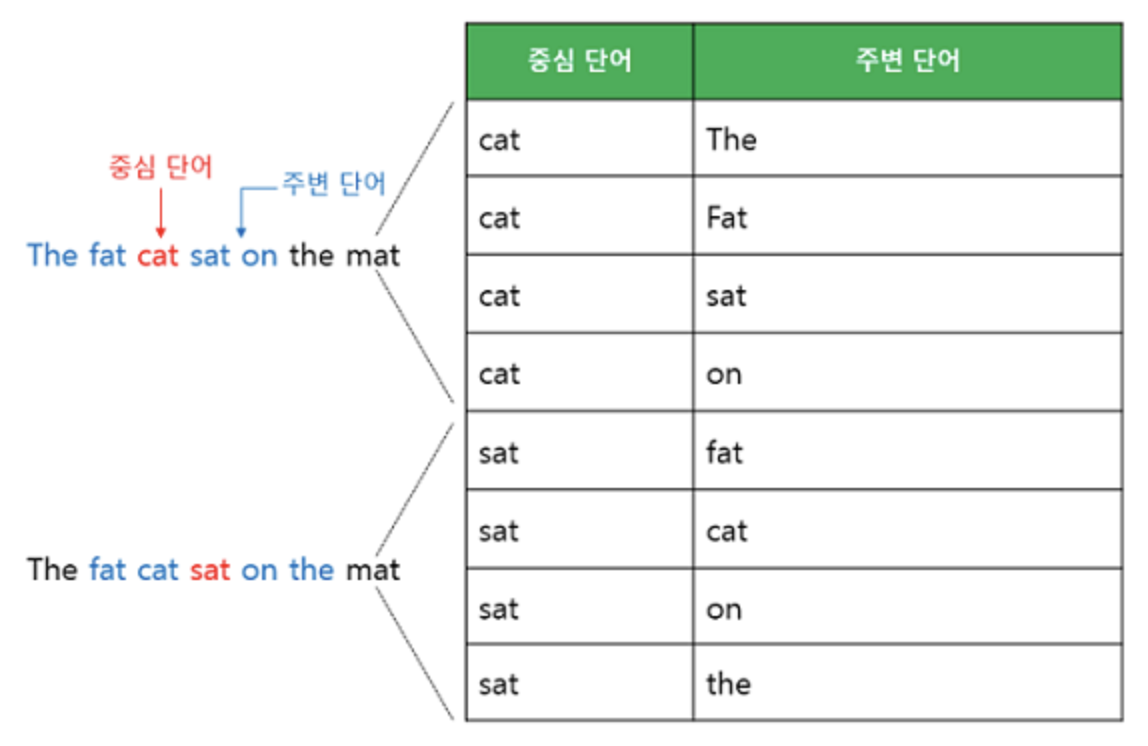 skip-gram에서 window size=2일 때 sliding window 방법으로 dataset을 만드는 과정
skip-gram에서 window size=2일 때 sliding window 방법으로 dataset을 만드는 과정
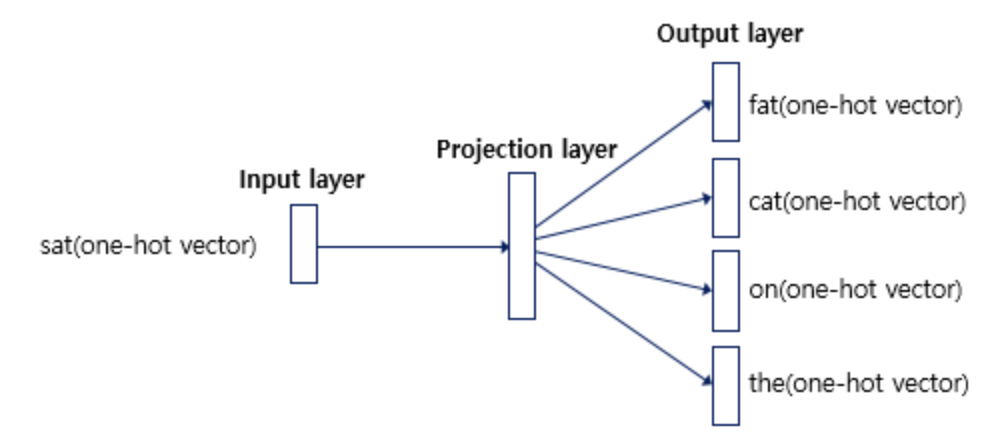 skip-gram 인공신경망
skip-gram 인공신경망

Leave a comment